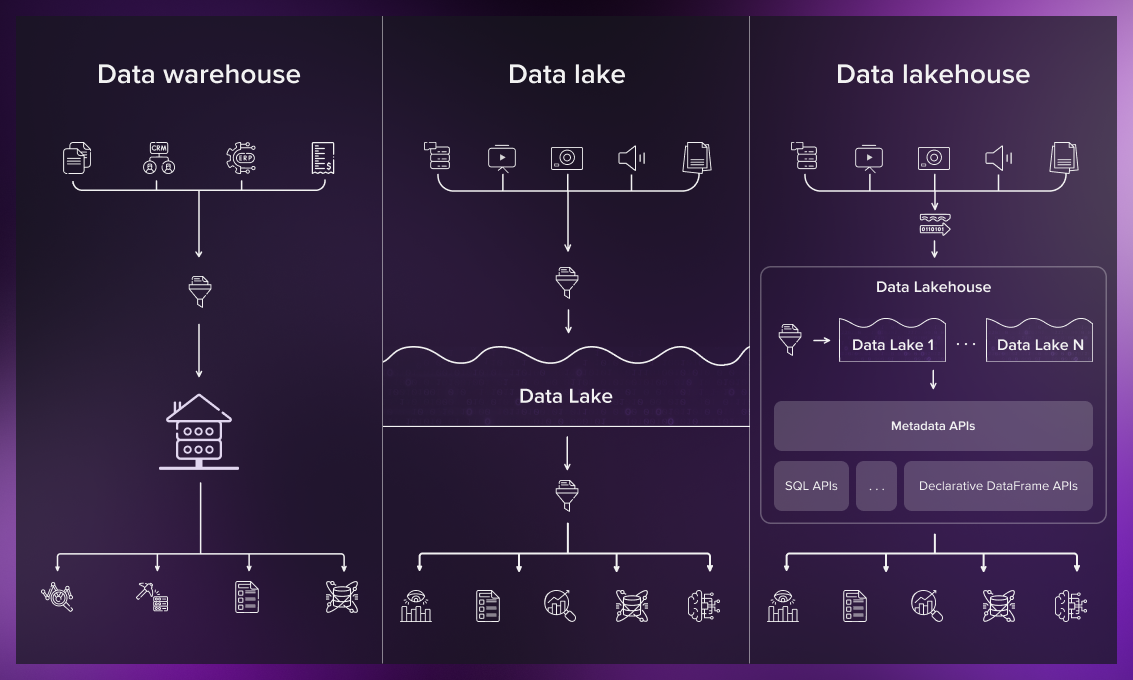
Data Warehouse is a combination of technologies that collects and manages data extracted from transactional systems or data which consists of quantitative metrics with attributes for strategically using it to provide meaningful business insights. Data Warehouse is used in the process of transforming data into information. Storing data in such an architecture is costlier and time-consuming. The traditional ETL process is used to handle data.
Data Lake on the other hand is a storage repository to store large amount of structured, semi-structured and unstructured data. The data is stored in its native / raw format with no fixed limits. Data storage is relatively inexpensive and flexible with Data Lake architecture. Data Lakes use ELT process to handle the data.
Data Lakehouse acts as a single platform for data warehousing and Data Lake.
Data Lakehouse -Overcoming the limitations of DataWarehouse and DataLake!
Data Warehouse was the first architecture that allowed structured data to be stored for specific business intelligence and reporting purposes. This information storage architecture served the businesses right from the 1980s until Big data took over the mainstream.
With the advent of Big data, Businesses started to tap on even the unstructured data. The raw, unprocessed data was very difficult to deal with. The main sources of these messy unstructured data were pictures, videos, or audio recordings. As this type of data typically made upto 80 to 90% of the information available to organisations, it added value at a massive rate to the decision making process.
The data contained in customer email communications or the live video footage coming in from the CCTV holds a phenomenal amount of value that could benefit the organisations. However, this kind of data cannot be stored in the traditional ordered way of storing the structured data as in the Data Warehouse architecture.
To overcome this limitation, a new architecture evolved known as Data Lake. This allowed unstructured data to be stored in its native format and could be used for processing to get insights from it right away.
Data Lake has undoubtedly been the most powerful architecture to handle the unstructured data until Data Lakehouse came into existence. Even though Data Lake is the most flexible architecture, it had its limitations like the data swamp issues where governance and privacy might get compromised. It also involved technical complexities in creating systems that can ingest data in multitude of schemas and formats.
This brings us to the most trending and emerging architecture that addresses the limitations of both Data Lakes and Data Warehouses putting together the best elements of both.
Data Lakehouse is built to support both structured and unstructured data making it easier for the businesses to house one data repository in place of both warehouse and lake infrastructure.
Data Lakehouse is different from the Data Lake with the fact that it enables structure and schema like in Data Warehouse to be applied to the unstructured data that is typically stored in a Data Lake. This acts like a unified platform where it feeds multiple domains like BI analytics, Artificial intelligence, Machine learning and many more use cases. All of this is possible only because of the fact that it supports different formats of data.
Features of Data Lakehouse
Data Reliability -Improved data reliability with fewer cycles of data transfer between different systems, thereby overcoming the data quality issues.
Cost Effective Storage -Since the data is stored in relatively cheap object stores, such as S3, blob, etc. Data Lakehouse offers a cost-effective storage in comparison to its prequels Data warehouse / Data Lake.
Scalability by Decoupling Storage and Compute -The Lakehouse architecture supports separate clusters for storage and compute respectively which allows for concurrent query runs on different computing nodes.
Direct BI Support -Data can be directly accessed from data storage layer for processing.
Architectural layers of Data Lakehouse
Ingestion Layer -Extracting the data from a variety of sources with the unification of stream and batch data processing capabilities and delivering it to the storage layer.
Storage Layer -Solution design includes storing the data in low-cost cloud object stores like AWS S3 enabling the client tools to read this objects directly using open file formats. The component tools can apply the schema kept in the metadata layer while reading structured/ semi-structured data.
Catalog / Metadata Layer -this layer manages the metadata. This layer also allows for Data Warehouse schema architectures like star/ snowflake schemas. Schema management involves schema enforcement , schema evolution, data governance and auditing functionality for a high quality data pipeline.
Processing Layer -Depending on the use case, different kinds of available services can be used to perform tasks i.e., ETL jobs
Consumption Layer -This layer provides interfaces for use-cases like Analytics, BI/ML where visualizations and Dashboards are created to gain insights.